Abstract
We present FlashLips, a two-stage, mask-free lip-sync system that decouples
lips control from rendering and achieves real-time performance, with our U-Net variant running
at over 100 FPS on a single GPU, while matching the visual quality of larger
state-of-the-art models.
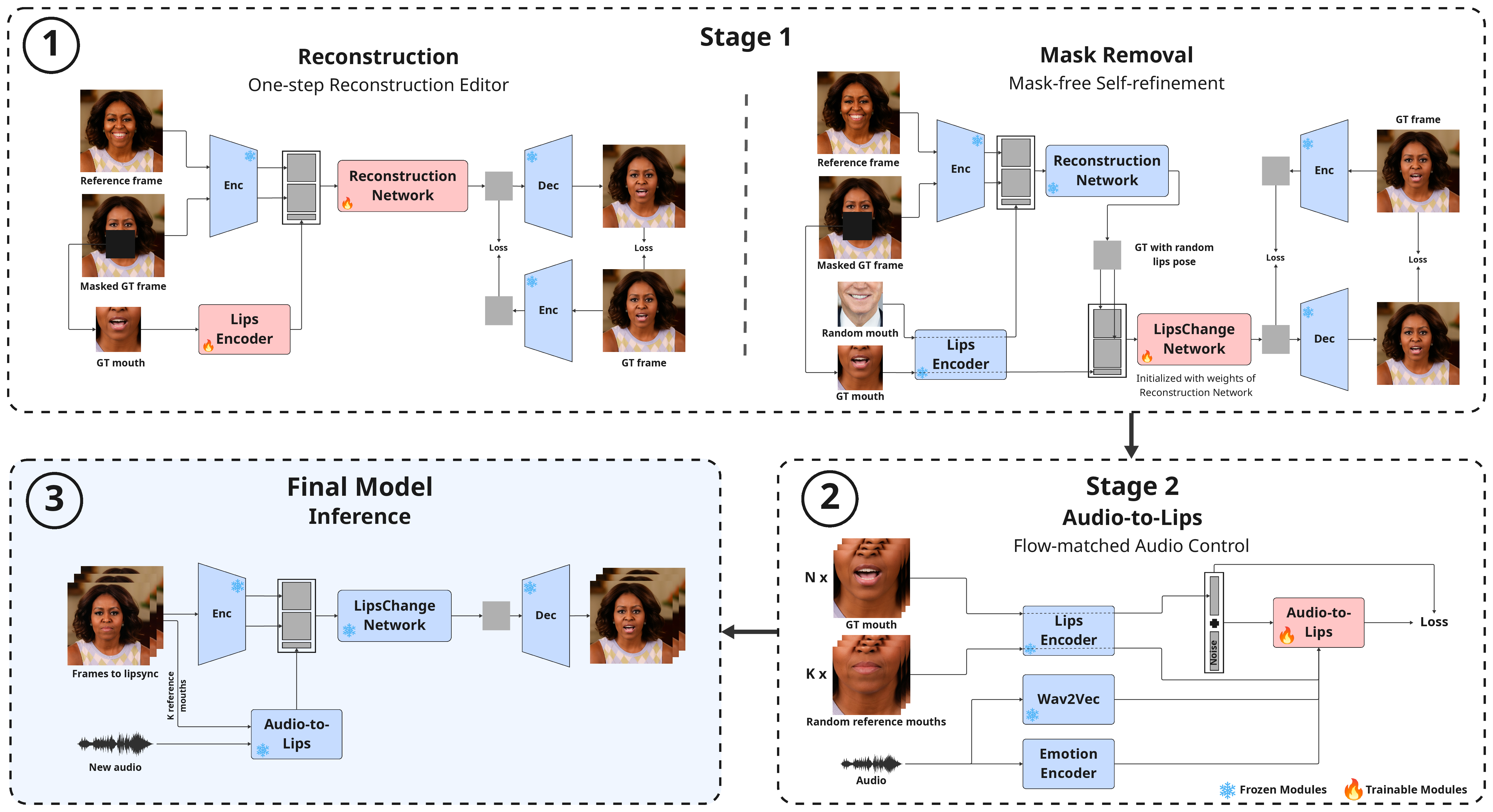
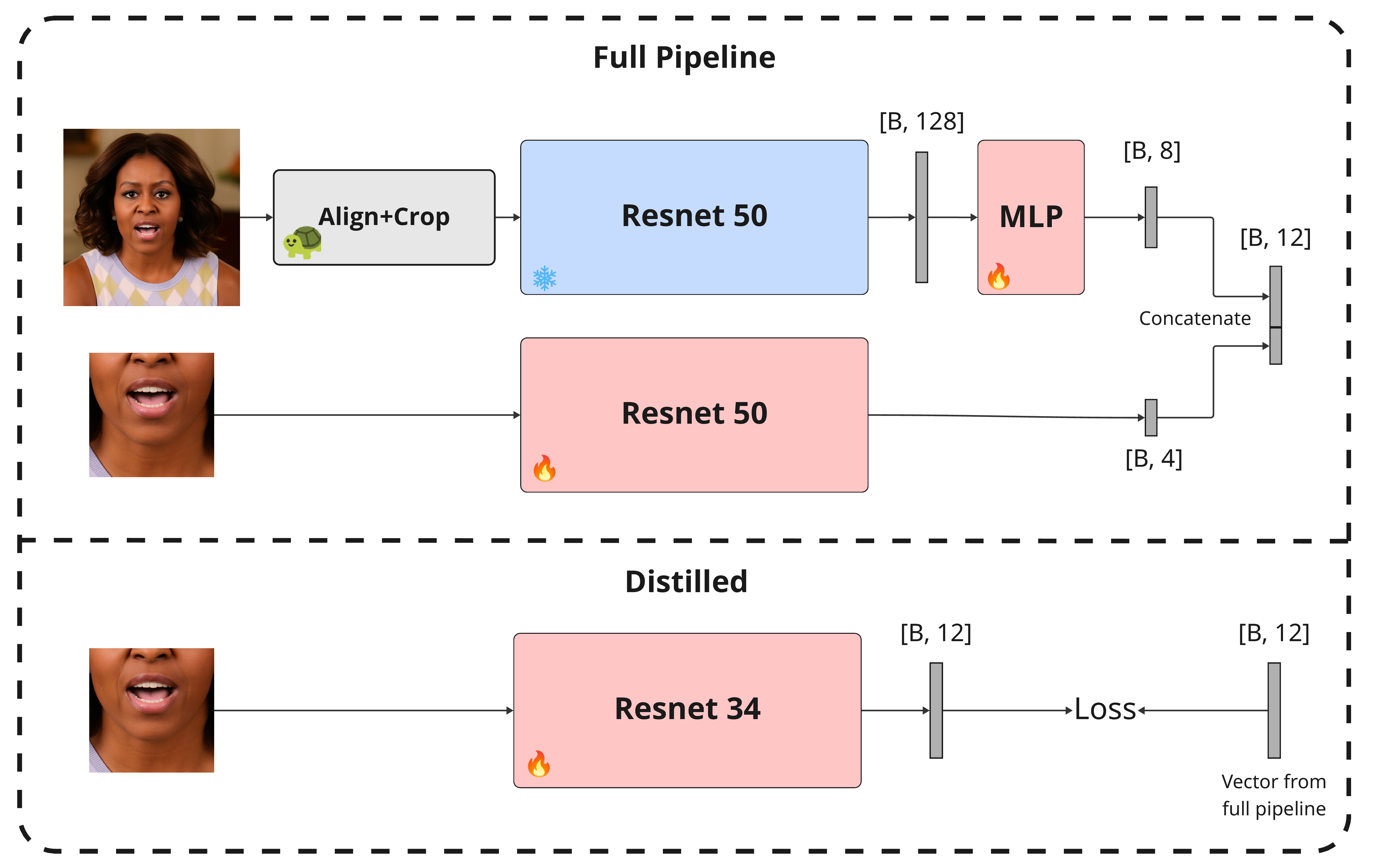
Stage 1 is a compact, one-step latent-space editor that reconstructs an image using a reference identity,
a masked target frame, and a low-dimensional lips-pose vector, trained purely with reconstruction
losses — no GANs or diffusion. To remove explicit masks at inference, we use self-supervision via
mouth-altered target variants as pseudo ground truth, teaching the network to localize lip edits
while preserving the rest. Stage 2 is an audio-to-pose transformer trained with a flow-matching
objective to predict lips-pose vectors from speech. Together, these stages form a simple and stable
pipeline that combines deterministic reconstruction with robust audio control, delivering high
perceptual quality and faster-than-real-time speed.